

Classification and Clustering Analysis: An Analysis of Texts from the Gutenberg Corpora
The full code can be found here.
Natural Language Processing (NLP) allows for the large scale analysis of subjective human language using machine learning. Any industry that aggregates large amount of text through the internet stands to gain from the imlementation of NLP. As the amount of text data increases exponentially, companies rely on machine learning techniques such as natural language processing to gather insights from this data that can help make decisions that lead to growth and profit. A lot of this text data comes from multiple sources and is often disorganized, making it more difficult for supervised learning techniques to utilize. Unsupervised learning methods allow for text data to be analyzed despite this disorganization. Unsupervised learning achieves this by organizing the data in a way that allows it to be better analyzed and by generating more versions of this text data that is more palatable to machine learning algorithms. To better understand how unsupervised learning techniques can be utilized in NLP, I am interested in using unsupervised feature generation techniques to analyze texts from the Gutenberg Corpora written by various authors.
In this study, classification and clustering of excerpts from various texts was done following unsupervised feature generation. Excerpts were classified as having been written by a specific author and excerpts were clustered based on author. Clusters were analyzed based on their ability to group authors’ excerpts together. The different classification models were compared to better understand their ability to accurately predict author using multiple forms of statistical evaluation. The process used to undertake this study is as follows:
Initiation and Data Preprocessing
- Import Packages and Files
- Parse and Label Excerpts
- Vectorization and Feature Reduction
Clustering Analysis
- Selecting Appropriate Clustering Method
- Analyzing 10 Clusters Made Using K Means
- Analyzing Holdout Group
Modeling the Data
- Using Bag of Words
- Using TF-IDF
Initiation and Data Preprocessing
The data used in this study is taken from texts found in the Gutenberg corpora. Excerpts taken from the writing of the ten authors were used in clustering and classification. Excerpts were labeled using the authors’ last names: Chesterton, Bryant, Edgeworth, Austen, Whitman, Milton, Melville, Carroll, Shakespeare, and Burgess. After labeling, two sets of features were created using bag of words and TF-IDF. Both sets of features were reduced using singular value decomposition to reduce computational complexity and remove noise.
101 excerpts with about 600 characters each were extracted for each author.
chesterton:
poetry. These things were there, in their place; but one felt that they were never allowed out of their place. Luxury was there: there stood upon a special table eight or ten boxes of the best cigars; but they were built upon a plan so that the strongest were always nearest the wall and the mildest nearest the window. A tantalus containing three kinds of spirit, all of a liqueur excellence, stood always on this table of luxury; but the fanciful have asserted that the whisky, brandy, and rum seemed always to stand at the same level. Poetry was there: the left-hand corner of the
bryant:
"It's the Rain, and I want to come in," said a soft, sad, little voice. "No, you can't come in," the little Tulip said. By and by she heard another little _tap, tap, tap_ on the window-pane. "Who is there?" she said. The same soft little voice answered, "It's the Rain, and I want to come in!" "No, you can't come in," said the little Tulip. Then it was very still for a long time. At last, there came a little rustling, whispering sound, all round the window: _rustle, whisper, whisper_. "Who is there?" said the little Tulip. "It's the Sunshine," said a little,
edgeworth:
gathered round the fire eating their potatoes and milk for supper. "Bless them, the poor young creatures!" said the widow, who, as she lay on her bed, which she knew must be her deathbed, was thinking of what would become of her children after she was gone. Mary stopped her wheel, for she was afraid that the noise of it had wakened her mother, and would hinder her from going to sleep again. "No need to stop the wheel, Mary, dear, for me," said her mother, "I was not asleep; nor is it THAT which keeps me from sleep. But don't overwork yourself, Mary." "Oh, no fear of that,"
austen:
woman as governess, who had fallen little short of a mother in affection. Sixteen years had Miss Taylor been in Mr. Woodhouse's family, less as a governess than a friend, very fond of both daughters, but particularly of Emma. Between _them_ it was more the intimacy of sisters. Even before Miss Taylor had ceased to hold the nominal office of governess, the mildness of her temper had hardly allowed her to impose any restraint; and the shadow of authority being now long passed away, they had been living together as friend and friend very mutually attached, and Emma doing just what she liked;
whitman:
alone nor brain alone is worthy for the Muse, I say the Form complete is worthier far, The Female equally with the Male I sing. Of Life immense in passion, pulse, and power, Cheerful, for freest action form'd under the laws divine, The Modern Man I sing. } As I Ponder'd in Silence As I ponder'd in silence, Returning upon my poems, considering, lingering long, A Phantom arose before me with distrustful aspect, Terrible in beauty, age, and power, The genius of poets of old lands, As to me directing like flame its eyes, With finger pointing to many immortal songs, And menacing
milton:
intends to soar Above th' Aonian mount, while it pursues Things unattempted yet in prose or rhyme. And chiefly thou, O Spirit, that dost prefer Before all temples th' upright heart and pure, Instruct me, for thou know'st; thou from the first Wast present, and, with mighty wings outspread, Dove-like sat'st brooding on the vast Abyss, And mad'st it pregnant: what in me is dark Illumine, what is low raise and support; That, to the height of this great argument, I may assert Eternal Providence, And justify the ways of God to men. Say first for Heaven hides nothing from thy view,
melville:
the signification of the word, you deliver that which is not true." HACKLUYT "WHALE. ... Sw. and Dan. HVAL. This animal is named from roundness or rolling; for in Dan. HVALT is arched or vaulted." WEBSTER'S DICTIONARY "WHALE. ... It is more immediately from the Dut. and Ger. WALLEN; A.S. WALW-IAN, to roll, to wallow." RICHARDSON'S DICTIONARY KETOS, GREEK. CETUS, LATIN. WHOEL, ANGLO-SAXON. HVALT, DANISH. WAL, DUTCH. HWAL, SWEDISH. WHALE, ICELANDIC. WHALE, ENGLISH. BALEINE, FRENCH. BALLENA, SPANISH. PEKEE-NUEE-NUEE, FEGEE. PEKEE-NUEE-NUEE, ERROMANGOAN. EXTRACTS (Supplied by
carroll:
Rabbit with pink eyes ran close by her. There was nothing so VERY remarkable in that; nor did Alice think it so VERY much out of the way to hear the Rabbit say to itself, 'Oh dear! Oh dear! I shall be late!' (when she thought it over afterwards, it occurred to her that she ought to have wondered at this, but at the time it all seemed quite natural); but when the Rabbit actually TOOK A WATCH OUT OF ITS WAISTCOAT-POCKET, and looked at it, and then hurried on, Alice started to her feet, for it flashed across her mind that she had never before seen a rabbit with either a waistcoat-
shakespeare:
heare them. Stand: who's there? Hor. Friends to this ground Mar. And Leige-men to the Dane Fran. Giue you good night Mar. O farwel honest Soldier, who hath relieu'd you? Fra. Barnardo ha's my place: giue you goodnight. Exit Fran. Mar. Holla Barnardo Bar. Say, what is Horatio there? Hor. A peece of him Bar. Welcome Horatio, welcome good Marcellus Mar. What, ha's this thing appear'd againe to night Bar. I haue seene nothing Mar. Horatio saies, 'tis but our Fantasie, And will not let beleefe take hold of him Touching this dreaded sight, twice seene of vs, Therefore I haue
burgess:
trying to make up his mind what would taste best, he was listening to the sounds that told of the waking of all the little people who live in the Green Forest. He heard Sammy Jay way off in the distance screaming, "Thief! Thief!" and grinned. "I wonder," thought Buster, "if some one has stolen Sammy's breakfast, or if he has stolen the breakfast of some one else. Probably he is the thief himself." He heard Chatterer the Red Squirrel scolding as fast as he could make his tongue go and working himself into a terrible rage. "Must be that Chatterer got out of bed the wrong way
Above is an example of what the excerpts from each author looked like prior to unsupervised feature generation.
Clustering Analysis
Clustering was done on the TF-IDF vectorized features with 25% of the excerpts reserved as a holdout group to test the stability of the clusters. Author labels were dropped prior to clustering so the excerpts would be clustered based on their contents as opposed to the pre-generated label.
Selecting Appropriate Clustering Method
The appropriate clustering method was selected based on the number of clusters generated by a particular method and sillhouette scores.
Mean Shift yielded a single cluster which would not be useful for analysis.
Silhouette scores for K Means:
7 clusters: 0.18654454819897806
8 clusters: 0.20824216402018073
9 clusters: 0.23012152834894517
10 clusters: 0.24786794516850177
K means was conducted for multiple numbers of clusters. K means with 10 clusters was chosen because it yielded a sufficiently high sillhouette score and because having the same number of clusters as author labels would be beneficial to analysis.
Analyzing Clusters
K-means generated labels were compared to the original author labels to analyze the ability of K-means to group the excerpts based on their content.
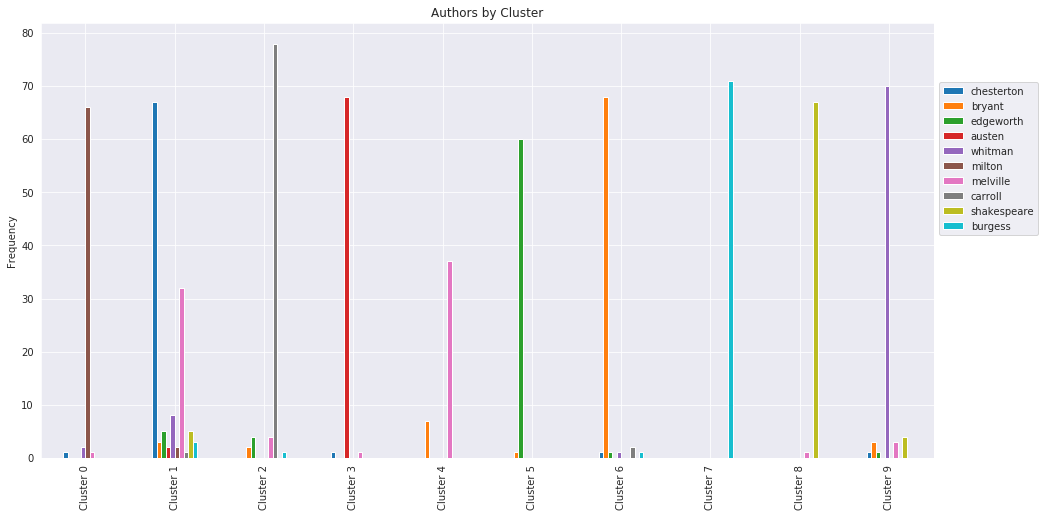
Above is a bar graph visualizing the contents of individual clusters made using K-means. Cluster names refer to the numerical label assigned to each cluster and have no significance other than differentiating clusters from eachother.
The clusters primarily differentiated excerpts based on the author of the excerpts. This can be seen by the fact that the clusters each have a significantly higher number of excerpts from a single author. Bear in mind that the author names were not taken into account during the clustering process so these distinctions were made solely on the content of the excerpts.
While each cluster contained a majority of an individual author’s works there are some discrepancies that should be noted. A large portion of Melville’s writings were grouped in the cluster mostly containing Chesterton’s excerpts. This implies that there were similarities between a lot of Melville’s and Chesterton’s excerpts that clustering had trouble discerning. The majority of excerpts that weren’t clustered in the group with a majority of their author’s excerpts fell into the Chesterton Cluster (cluster 1). However with the exception of Melville’s excerpts this was a very small amount of non-Chesterton works in the cluster 1.
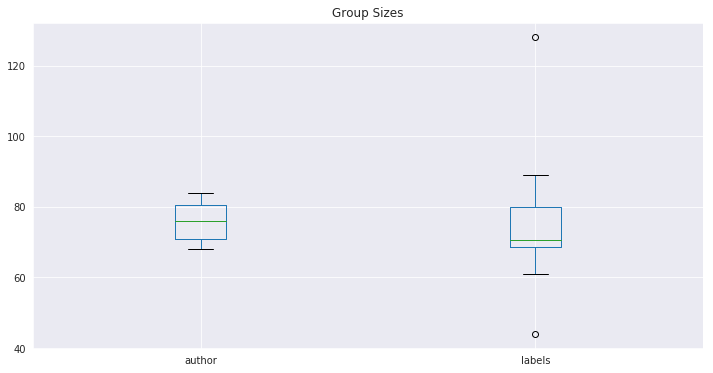
Above are boxplots reflecting the number of observations that had a specific author label or cluster generated label, respectively. These can be refered to as author group sizes and cluster sizes respectively. The median author group sizes and cluster sizes are relatively close. However the range of the cluster group sizes is much larger with outliers in both directions. This is reflective of discrepancies between author and cluster labels. The high outlier in the cluster label sizes is the size of cluster 1, The cluster containing a majority of Chesterton’s works. This cluster is large because it also contains a significant amount of Melville’s works. The low outlier in the cluster group sizes refer to the cluster 4, the cluster containing a majority of Melville’s works. This Cluster is small because many of Melvilles works were grouped in cluster 1.
Percent of Author's Excerpts that were Clustered Together
{'milton': 0.9705882352941176, 'chesterton': 0.9436619718309859, 'carroll': 0.9629629629629629, 'austen': 0.9714285714285714, 'melville': 0.46835443037974683, 'edgeworth': 0.8450704225352113, 'bryant': 0.8095238095238095, 'burgess': 0.9342105263157895, 'shakespeare': 0.881578947368421, 'whitman': 0.8641975308641975}
The above percentages refer to the percentage of author’s excerpts that were grouped together in the cluster that contained a majority of that author’s works. This can be percieved as a way to quantify the ability of the clustering method to group authors’ excerpts together. The majority of the authors’ excerpts were grouped together with the exception of Melville’s excerpts; many of which were grouped with Chesterton’s excerpts. With the exception of Melville’s works, clustering was able to group authors’ excerpts with an accuracy of over 80%.
Testing Holdout Group
The 25% holdout group was analyzed to better understand the stability of K-means when it comes to clustering the texts.
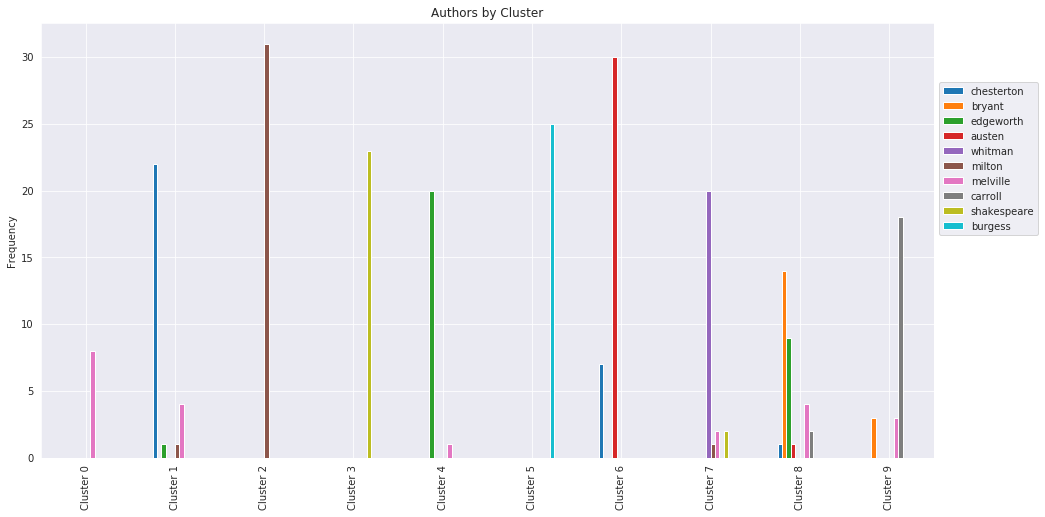
Above is a bar graph visualizing the contents of individual clusters made using the K-means on the holdout group. Cluster names refer to the numerical label assigned to each cluster and have no significance other than differentiating clusters from eachother.
The clusters still primarily differentiated excerpts based on the author of the excerpts. This can be seen by the fact that the clusters each have a significantly higher number of excerpts from a single author.
While each cluster was able to contain a majority of a individual author’s works in the holdout group there are more discrepancies than in the original clusters. As with the original clusters, a large portion of Melville’s excerpts were grouped in the cluster containing mostly Chesterton’s excerpts. A lot of Edgeworth’s excerpts were also grouped with Bryant’s excerpts in cluster 8 as well.
Percent of Author's Excerpts that were Clustered Together
{'melville': 0.36363636363636365, 'chesterton': 0.7333333333333333, 'milton': 0.9393939393939394, 'shakespeare': 0.92, 'edgeworth': 0.6666666666666666, 'burgess': 1.0, 'austen': 0.967741935483871, 'whitman': 1.0, 'bryant': 0.8235294117647058, 'carroll': 0.9}
As can be seen by the cluster percentages and bar graph, the holdout group clusters were less stable than the original clusters (especially when it came to grouping Edgeworth’s excerpts). Despite the drop in stability, the holdout group clusters each still contained a majority if a single actor’s excerpts. Overall, clustering using K-means was reliably able to differentiate the text samples of different authors.
Modeling the Data using Bag of Words
Neural Network
accuracy score:
0.932806324110672
cross validation:
[0.90967742 0.94736842 0.94039735 0.95364238 0.9527027 ]
confusion matrix:
[[33 0 0 0 0 1 0 0 0 0]
[ 0 26 0 0 0 0 0 0 0 0]
[ 0 0 20 0 0 0 0 0 0 0]
[ 0 0 0 23 0 0 2 0 0 0]
[ 0 0 0 0 21 0 0 0 0 0]
[ 0 2 0 0 0 15 0 0 0 0]
[ 0 0 0 1 0 0 15 0 0 0]
[ 0 0 0 0 0 0 4 30 0 1]
[ 0 0 0 0 0 0 0 0 27 0]
[ 0 0 0 0 4 0 2 0 0 26]]
precision recall f1-score support
austen 1.00 0.97 0.99 34
bryant 0.93 1.00 0.96 26
burgess 1.00 1.00 1.00 20
carroll 0.96 0.92 0.94 25
chesterton 0.84 1.00 0.91 21
edgeworth 0.94 0.88 0.91 17
melville 0.65 0.94 0.77 16
milton 1.00 0.86 0.92 35
shakespeare 1.00 1.00 1.00 27
whitman 0.96 0.81 0.88 32
accuracy 0.93 253
macro avg 0.93 0.94 0.93 253
weighted avg 0.94 0.93 0.93 253
The neural network had the best performance out of all of the models run with features generated by bag of words. Cross validation showed few signs of overfitting with this model. The strength of this model when it comes to making predictions using this data comes from its ability to generate predictions based on individual records and adjusting its weights based on the results. This is especially useful for text data where similar features may have different implications based on the prescence of other features in the same record. Naive bayes had similar accuracy scores but strong signs of overfitting. KNN and the decision tree performed poorly with this data. The model types likely lacked the power to discern between various groups of features. Using bag of words may be advantageous in situations where texts are smaller and more domain specific. This is because high frequency features in these situations may not be indicative of non-meaningful variance.
Modeling the Data using TF-IDF
Neural Network
accuracy score:
0.9565217391304348
cross validation:
[0.94193548 0.94736842 0.94701987 0.9602649 0.98648649]
confusion matrix:
[[34 0 0 0 0 0 0 0 0 0]
[ 0 26 0 0 0 0 0 0 0 0]
[ 0 0 20 0 0 0 0 0 0 0]
[ 0 0 0 25 0 0 0 0 0 0]
[ 0 0 0 0 21 0 0 0 0 0]
[ 0 0 0 0 0 17 0 0 0 0]
[ 0 0 0 0 0 0 14 0 0 2]
[ 0 0 0 0 0 0 0 33 0 2]
[ 0 0 0 0 0 0 0 0 27 0]
[ 0 0 0 0 5 0 1 1 0 25]]
precision recall f1-score support
austen 1.00 1.00 1.00 34
bryant 1.00 1.00 1.00 26
burgess 1.00 1.00 1.00 20
carroll 1.00 1.00 1.00 25
chesterton 0.81 1.00 0.89 21
edgeworth 1.00 1.00 1.00 17
melville 0.93 0.88 0.90 16
milton 0.97 0.94 0.96 35
shakespeare 1.00 1.00 1.00 27
whitman 0.86 0.78 0.82 32
accuracy 0.96 253
macro avg 0.96 0.96 0.96 253
weighted avg 0.96 0.96 0.96 253
The neural network had the best performance out of all of the models run with features generated by TF-IDF. The neural network with TF-IDF features also outperformed the neural network with bag of words features, making it the strongest supervised model in the study. Cross validation showed few signs of overfitting with this model. TF-IDF gave the neural network more accurate weights of the representativeness of each feature allowing for the neural network to make predictions with less error. This helped the processing of the text data for the neural network by reducing noise created by frequent but uninformative features. The accuracy and cross validation scores were higher in geneneral for the TD-IDF models but the same trends existed between model most types with the exception of KNN. KNN with TF-IDF yielded significantly higher accuracy than KNN with bag of words. The reduction of noise that this form of feature selection offers likely allowed KNN to process observations using more representative neighboring datapoints.
Analysis and Conclusion
Both classification and clustering were able to reliably label the excerpts by author in this study. The neural network built on TF-IDF features, the best performing model, had over a 95% accuracy and regularly labeled each author’s excerpts correctly over 80% of the time. Clustering was able to yield high accuracy as well, grouping over 80% of each author’s excerpts together with the exception of Melville’s excerpts. Melville’s excerpts was consistently the least consistently labeled across all models, implying that discrepancies in its labeling are due to the data itsself rather than the method of feature preparation and classification. Modeling did have the advantage of being more accurate but clustering was able to show strong reliability even in the abscence of labels.
This established the relative ability of clustering and modeling unsupervised learning generated features to classify the authors of writing samples. By being able to reliably label data using unsupervised and supervised methods, large amounts of text can be analyzed, even in the abscence of pre-established labels. A condition often found in real-world data. The next step in using this data to discern the source of the text data would be to collect more text from different authors and more data about the context in which the text was generated. Afterwards the study can be expanded to include different types of feature preparation.
Understanding how to better utilize unsupervised modeling techniques to predict author, will give insight as to what kind of people are generating different types of texts. This can be practically be applied to consumer data such as reviews and other types of user generated text. This can allow for more direct marketing to users or changes in products that better match how services are used. Being able to utilize readily available data that isn’t always processed and labeled, allows for revenue generating decisions to be made at very little cost to stakeholders.